Example: Splitting JSON Files with RecursiveJSONSplitter¶
When working with structured data such as invoices, user records, or any other JSON document, it's often necessary to split the data into manageable chunks for downstream processing, storage, or LLM ingestion. SplitterMR provides the RecursiveJSONSplitter, an splitter which divides a JSON structure into key-based chunks, preserving the hierarchy and content integrity. Let's see how it works!
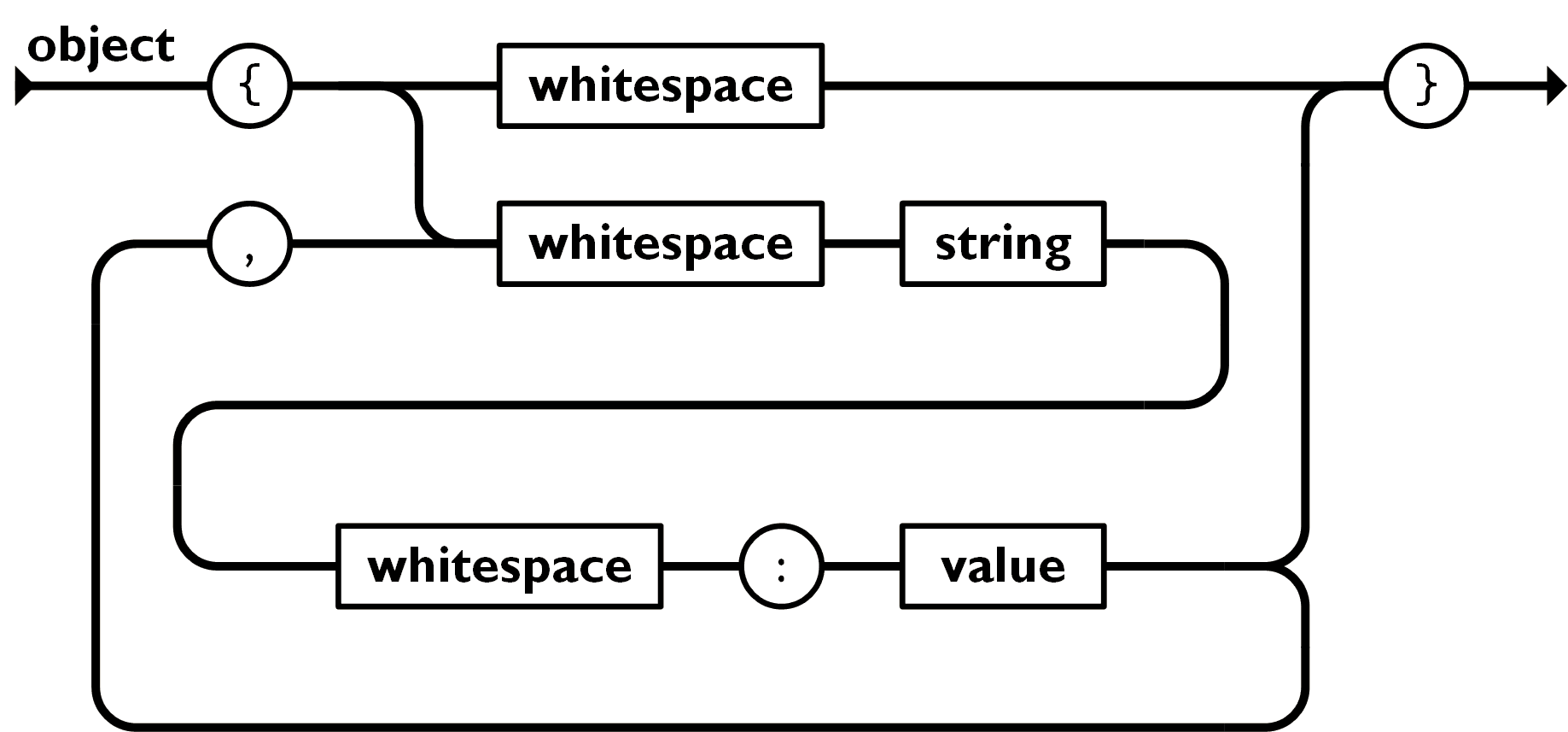
Step 1: Read the JSON Document¶
First, use the VanillaReader to load the JSON file. You can use other Reader methods as your choice. Note that you can read from an URL, Path or variable.
from splitter_mr.reader import VanillaReader
file = "https://raw.githubusercontent.com/andreshere00/Splitter_MR/refs/heads/main/data/invoices.json" # Path to your JSON file
reader = VanillaReader()
reader_output = reader.read(file)
print(reader_output.model_dump_json(indent=4)) # Show metadata and summary
{
"text": "[\n {\n \"id\": 1,\n \"name\": \"Johnson, Smith, and Jones Co.\",\n \"amount\": 345.33,\n \"Remark\": \"Pays on time\"\n },\n {\n \"id\": 2,\n \"name\": \"Sam \\\"Mad Dog\\\" Smith\",\n \"amount\": 993.44,\n \"Remark\": \"\"\n },\n {\n \"id\": 3,\n \"name\": \"Barney & Company\",\n \"amount\": 0,\n \"Remark\": \"Great to work with\\nand always pays with cash.\"\n },\n {\n \"id\": 4,\n \"name\": \"Johnson's Automotive\",\n \"amount\": 2344,\n \"Remark\": \"\"\n }\n]",
"document_name": "invoices.json",
"document_path": "https://raw.githubusercontent.com/andreshere00/Splitter_MR/refs/heads/main/data/invoices.json",
"document_id": "81fcaa4b-5bdb-472b-bd5c-e37f3f386463",
"conversion_method": "json",
"reader_method": "vanilla",
"ocr_method": null,
"page_placeholder": null,
"metadata": {}
}
Accessing to the text attribute you find the following JSON object:
print(reader_output.text)
[
{
"id": 1,
"name": "Johnson, Smith, and Jones Co.",
"amount": 345.33,
"Remark": "Pays on time"
},
{
"id": 2,
"name": "Sam \"Mad Dog\" Smith",
"amount": 993.44,
"Remark": ""
},
{
"id": 3,
"name": "Barney & Company",
"amount": 0,
"Remark": "Great to work with\nand always pays with cash."
},
{
"id": 4,
"name": "Johnson's Automotive",
"amount": 2344,
"Remark": ""
}
]
This is a JSON dataset with some sample invoices.
| id | name | amount | Remark |
|---|---|---|---|
| 1 | Johnson, Smith, and Jones Co. | 345.33 | Pays on time |
| 2 | Sam "Mad Dog" Smith | 993.44 | |
| 3 | Barney & Company | 0 | Great to work with and always pays with cash. |
| 4 | Johnson's Automotive | 2344 |
Step 2: Split the JSON Document¶
To split the text, instantiate the RecursiveJSONSplitter and split the loaded JSON content:
from splitter_mr.splitter import RecursiveJSONSplitter
splitter = RecursiveJSONSplitter(chunk_size=100, min_chunk_size=20)
splitter_output = splitter.split(reader_output)
print(splitter_output.model_dump_json(indent=4)) # Show the SplitterOutput object
{
"chunks": [
"{\"0\": {\"id\": 1, \"name\": \"Johnson, Smith, and Jones Co.\", \"amount\": 345.33, \"Remark\": \"Pays on time\"}}",
"{\"1\": {\"id\": 2, \"name\": \"Sam \\\"Mad Dog\\\" Smith\", \"amount\": 993.44, \"Remark\": \"\"}}",
"{\"2\": {\"id\": 3, \"name\": \"Barney & Company\", \"amount\": 0, \"Remark\": \"Great to work with\\nand always pays with cash.\"}}",
"{\"3\": {\"id\": 4, \"name\": \"Johnson's Automotive\", \"amount\": 2344, \"Remark\": \"\"}
...
b6-0558-444d-a81d-78aa46553e50"
],
"document_name": "invoices.json",
"document_path": "https://raw.githubusercontent.com/andreshere00/Splitter_MR/refs/heads/main/data/invoices.json",
"document_id": "81fcaa4b-5bdb-472b-bd5c-e37f3f386463",
"conversion_method": "json",
"reader_method": "vanilla",
"ocr_method": null,
"split_method": "recursive_json_splitter",
"split_params": {
"max_chunk_size": 100,
"min_chunk_size": 20
},
"metadata": {}
}
To inspect every chunk individually, print them as follows:
import json
for i, c in enumerate(splitter_output.chunks, 1):
data = next(iter(json.loads(c).values()))
print(f"{'=' * 40} Chunk {i} {'=' * 40}\n{json.dumps(data, indent=4)}\n")
======================================== Chunk 1 ========================================
{
"id": 1,
"name": "Johnson, Smith, and Jones Co.",
"amount": 345.33,
"Remark": "Pays on time"
}
======================================== Chunk 2 ========================================
{
"id": 2,
"name": "Sam \"Mad Dog\" Smith",
"amount": 993.44,
"Remark": ""
}
======================================== Chunk 3 ========================================
{
"id": 3,
"name": "Barney & Company",
"amount": 0,
"Remark": "Great to work with\nand always pays with cash."
}
======================================== Chunk 4 ========================================
{
"id": 4,
"name": "Johnson's Automotive",
"amount": 2344,
"Remark": ""
}
In markdown format table:
| id | name | amount | Remark |
|---|---|---|---|
| 1 | Johnson, Smith, and Jones Co. | 345.33 | Pays on time |
| id | name | amount | Remark |
|---|---|---|---|
| 2 | Sam "Mad Dog" Smith | 993.44 |
| id | name | amount | Remark |
|---|---|---|---|
| 3 | Barney & Company | 0 | Great to work with and always pays with cash. |
| id | name | amount | Remark |
|---|---|---|---|
| 4 | Johnson's Automotive | 2344 |
And that's it! As you can see, a chunk for every row in the JSON table has been generated.
Note
All the objects obtained by the SplitterOutput .chunks attribute are dict. In case that you need to transform it into str elements, you need to process them with the instruction str(chunk[idx]).
Complete Script¶
import json
from splitter_mr.reader import VanillaReader
from splitter_mr.splitter import RecursiveJSONSplitter
file = "https://raw.githubusercontent.com/andreshere00/Splitter_MR/refs/heads/main/data/invoices.json"
reader = VanillaReader() # Load a Reader
reader_output = reader.read(file) # Read the file
print(reader_output) # ReaderOutput object
print(reader_output.text) # Visualize the file
splitter = RecursiveJSONSplitter(chunk_size = 100, min_chunk_size=20) # Instantiate the Splitter class
splitter_output = splitter.split(reader_output) # Split the text
print(splitter_output) # SplitterOutput object
# Visualize every chunk
for i, c in enumerate(splitter_output.chunks, 1):
data = next(iter(json.loads(c).values()))
print(f"{'='*40} Chunk {i} {'='*40}\n{json.dumps(data, indent=2)}\n")